Construcción, evaluación y uso del modelo
Para construir este modelo, adaptaremos al contexto multivariado la metodología propuesta por Box y Jenkins1 (1970), que consiste en el siguiente proceso iterativo:
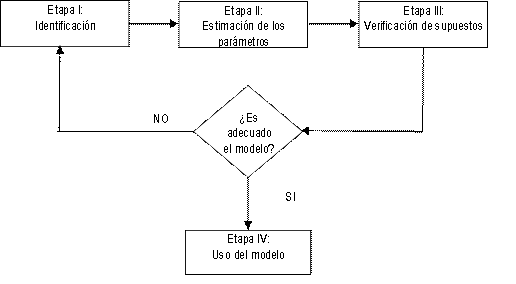
Fuente: Guerrero, Víctor (1993). Análisis estadístico de series de tiempo económicas.
Se detallará cada etapa del proceso a continuación:
- Identificación:
El principal objetivo que tiene esta etapa es determinar el orden del vector autorregresivo2 (el número de rezagos a incluir), basándonos en los criterios de información3 de Akaike, Schwartz y Hannan-Quinn. Además, se realiza para cada serie a incluir en el VAR la prueba KPSS4 donde probamos la hipótesis nula de que la serie en cuestión es un proceso estacionario (en tendencia) contra la alternativa que el proceso tiene una raíz unitaria. En caso de rechazarse la hipótesis nula de estacionariedad, buscamos una transformación que haga posible que la serie sea estacionaria para incorporarla al VAR5.
Se reportan a continuación los resultados de las pruebas KPSS para las variables sin transformar y para las variables transformadas:
Variables originales (en niveles):
|
Variable |
Estadístico de Contraste |
Valor Crítico (5%) |
Resultado |
|
RGDP |
0.2548 |
0.146 |
Rechazo |
|
RGPDI |
0.1670 |
0.146 |
Rechazo |
|
RPCEC |
0.2681 |
0.146 |
Rechazo |
|
ROILPRICE |
0.1561 |
0.146 |
Rechazo |
|
FEDFUNDS |
0.2055 |
0.146 |
Rechazo |
Fuente: Elaboración propia.
Variables transformadas:
| Variable |
Estadístico de Contraste |
Valor Crítico (5%) |
Resultado |
|
RGDP1 |
0.0639 |
0.146 |
Acepto |
|
RGPDI1 |
0.0683 |
0.146 |
Acepto |
|
RPCEC1 |
0.0610 |
0.146 |
Acepto |
|
DROILPRICE |
0.0836 |
0.146 |
Acepto |
|
RFEDFUNDS |
0.0686 |
0.146 |
Acepto |
Fuente: Elaboración propia.
Se decide por tanto incluir en el VAR las variables transformadas porque en todas se acepta la hipótesis nula de estacionariedad.
En cuanto al número de rezagos, se decide utilizar seis rezagos de acuerdo a los criterios de información:
|
Retardos |
AIC |
BIC |
HQC |
|
1 |
-16.021716 |
-15.485461* |
-15.804250 |
|
2 |
-16.335253 |
-15.352118 |
-15.936565 |
|
3 |
-16.355109 |
-14.925094 |
-15.775200 |
|
4 |
-16.624438 |
-14.747543 |
-15.863307 |
|
5 |
-17.015366 |
-14.691602 |
-16.073024* |
|
6 |
-17.070810* |
-14.300156 |
-15.947236 |
|
7 |
-16.945534 |
-13.728000 |
-15.640737 |
|
8 |
-16.977121 |
-13.312708 |
-15.491103 |
Fuente: Elaboración propia.
Los asteriscos indican los mejores (es decir, los mínimos) valores de cada criterio de información, AIC = criterio de Akaike, BIC = criterio bayesiano de Schwartz y HQC = criterio de Hannan-Quinn.
- Estimación de parámetros:
En esta etapa se supone que ya hemos identificado el modelo, y que por ser adecuado, lo único que resta es encontrar los mejores valores de los parámetros para que el modelo represente apropiadamente a las series en consideración.
Como las variables explicativas son todas retardadas y bajo el supuesto de ausencia de autocorrelación con las perturbaciones aleatorias, el método de los mínimos cuadrados ordinarios (OLS) proporciona estimadores consistentes y eficientes.
![]()
Si hubiera correlaciones entre las distintas ecuaciones podría ser necesario el uso de métodos de estimación con información completa. Dado que no existen restricciones en la matriz de coeficientes (porque todas las variables aparecen incluidas en todas las ecuaciones). Métodos alternativos no serán más eficientes que los mínimos cuadrados ordinarios.
- Verificación de supuestos:
Dado que la metodología de los vectores autorregresivos es relativamente flexible y no hay ningún impedimento en el hecho de considerar endógenas a todas las variables, no es costumbre el análisis de los coeficientes de regresión estimados ni sus significancias estadísticas; tampoco la bondad de ajuste de las ecuaciones individuales (![]() y
y ![]() ). Pero sí es muy importante, que se cumpla el supuesto de ausencia de autocorrelación de los residuales de cada una de las ecuaciones individuales del modelo y la distribución normal multivariada de los mismos.
). Pero sí es muy importante, que se cumpla el supuesto de ausencia de autocorrelación de los residuales de cada una de las ecuaciones individuales del modelo y la distribución normal multivariada de los mismos.
En esta etapa también realizamos un chequeo de la estabilidad del modelo estimado mediante el análisis de los eigenvalores (raíces inversas) del polinomio autorregresivo del VAR. Dichas raíces conviene representarlas por medio de una tabla y/o de un círculo unitario. Adicionalmente, se realizó un contraste para determinar la existencia de efecto ARCH (Heteroscedasticidad Condicional Autorregresiva) en cada una de las ecuaciones individuales y una prueba de significancia conjunta del modelo (prueba χ2).
A continuación reportamos los resultados de las pruebas de autocorrelación, normalidad multivariada, estabilidad de los parámetros, la existencia de efecto ARCH y una prueba de significancia conjunta del modelo.
- Contraste de Multiplicador de Lagrange de autocorrelación hasta el orden 4.
H0 : No hay autocorrelación.
|
ECUACION |
ESTADISTICO DE CONTRASTE (LMF) |
VALOR CRITICO |
RESULTADO |
|
Ecuación 1 |
1.57497 |
2.43585 |
Acepto |
|
Ecuación 2 |
2.2835 |
2.43585 |
Acepto |
|
Ecuación 3 |
1.93981 |
2.43585 |
Acepto |
|
Ecuación 4 |
1.9596 |
2.43585 |
Acepto |
|
Ecuación 5 |
0.5954 |
2.43585 |
Acepto |
Fuente: Elaboración propia.
- Contraste de normalidad multivariada de Doornik – Hansen.
H0 : El vector de residuales tiene una distribución normal.
Matriz de correlación de los residuales (5 x 5).
|
1 |
0.64211 |
0.75299 |
0.30928 |
-0.13446 |
|
0.64211 |
1 |
0.14836 |
0.32394 |
0.015938 |
|
0.75299 |
0.14836 |
1 |
0.20502 |
-0.10098 |
|
0.30928 |
0.32394 |
0.20502 |
1 |
0.035359 |
|
-0.13446 |
0.015938 |
-0.10098 |
0.035359 |
1 |
Eigenvalores.
0.0773076
0.732018
0.843406
1.08535
2.26192
|
Estadístico de contraste |
Valor Crítico |
Resultado |
|
130.349 |
18.3070381 |
Rechazo |
Fuente: Elaboración propia.
- Raíces inversas del polinomio autorregresivo del VAR.

- Contraste de efecto ARCH hasta el orden 4.
H0 : No hay efecto ARCH.
|
ECUACION |
ESTADISTICO DE CONTRASTE ( |
VALOR CRITICO |
RESULTADO |
|
Ecuación 1 |
6.30184 |
9.4877 |
Acepto |
|
Ecuación 2 |
1.41961 |
9.4877 |
Acepto |
|
Ecuación 3 |
8.85636 |
9.4877 |
Acepto |
|
Ecuación 4 |
34.3616 |
9.4877 |
Rechazo |
|
Ecuación 5 |
3.6959 |
9.4877 |
Acepto |
Fuente: Elaboración propia.
- Prueba de significancia conjunta del modelo.
Para el sistema en conjunto:
H0: El retardo más largo es 5
H1: El retardo más largo es 6
|
ESTADISTICO DE CONTRASTE |
VALOR CRITICO |
RESULTADO |
|
60.1678 |
37.6524 |
Rechazo |
Fuente: Elaboración propia.
Observamos que se cumple el supuesto de ausencia de correlación serial en los residuales de cada una de las ecuaciones individuales, aunque no se satisface el supuesto de normalidad, no obstante, es de mayor importancia que el VAR cumpla con el supuesto de ausencia de correlación serial6. Podemos apreciar también que todos los eigenvalores (raíces inversas) del polinomio autorregresivo del VAR son menores que uno (caen dentro del círculo unitario) y por tal razón se considera que el sistema satisface la condición de estabilidad y estacionariedad. Rechazamos la hipótesis nula de no existencia de efecto ARCH, en la cuarta ecuación, sin embargo, el proceso asociado a los residuales de esta regresión, continúa siendo estacionario debido a que la definición de estacionariedad requiere solamente que las covarianzas incondicionales no sean función del tiempo. Finalmente, el estadístico χ2 fue alto en el modelo, lo que corrobora la significancia conjunta (y la elección adecuada del número de rezagos) de todas las variables que integran el sistema. Por tanto, concluimos que el modelo se considera adecuado.
- Uso del modelo:
Ya que hemos considerado adecuado el modelo, la siguiente etapa que sugiere la metodología Box – Jenkins es su utilización. En nuestro caso, el modelo construido permitirá en primer lugar efectuar el proceso de simulación, que consiste en determinar los efectos aislados de cada una de las variables sobre el resto. Para llevar a cabo el proceso de simulación utilizaremos dos herramientas que son: la función de impulso - respuesta y la descomposición de la varianza del error de predicción. Previo al análisis de la funciones de impulso – respuesta y al análisis de descomposición de la varianza del error de predicción, examinaremos la causalidad “a la Granger” para determinar el carácter unidireccional o bidireccional de las series de tiempo involucradas. Con esto se facilita conocer la existencia y dirección de transmisión entre dos series de tiempo.
Posteriormente, utilizaremos el modelo para efectuar un pronóstico dinámico (fuera de la muestra) para las tasas de crecimiento anuales de las variables: PIB real (RGDP1), Gasto de consumo personal real (RPCEC1) y Gasto de inversión privada bruta real (RGPDI1).
A continuación, expondremos en detalle en qué consisten las herramientas que se utilizan para el proceso de simulación y el resultado de los pronósticos dinámicos.
- Causalidad a la Granger:
Ha sido un problema muy común en economía determinar si los cambios en una variable son una causa de los cambios en otra. La idea subyacente básica es muy simple: Si por ejemplo X causa a Y, entonces los cambios en X deben preceder a los cambios en Y. Particularmente, para decir que “La variable X está causando a Y”, se deben de cumplir dos condiciones. En principio, X debe ayudar a predecir Y. En segundo lugar, Y no debe ayudar a predecir X. Debido a que si Y predice X y X predice Y (causalidad bidireccional), probablemente una o más variables distintas, seguramente, estén causando los cambios observados tanto para X como para Y7.
Para probar si X causa Y, se procede de la siguiente manera:
Probamos: ![]()
![]() (X no causa Y) ejecutando dos regresiones:
(X no causa Y) ejecutando dos regresiones:
Regresión sin restricción:![]()
Regresión restringida: ![]()
Usamos una estadística ![]() para probar la significancia conjunta de los parámetros estimados.
para probar la significancia conjunta de los parámetros estimados.
Segundo, probamos ![]() (Y no causa X) ejecutando las mismas regresiones anteriores permutando X e Y.
(Y no causa X) ejecutando las mismas regresiones anteriores permutando X e Y.
Se debe advertir que cuando se afirma: “X causa a Y” (a la Granger), no implica que Y sea el efecto o resultado de X. Sino que lo que en realidad estamos midiendo es precedencia y contenido informativo, no la implicancia que generalmente se le otorga al término causalidad8.
A continuación se reportan las pruebas de causalidad a la Granger efectuada sobre las variables:
|
Pruebas apareadas de causalidad a la Granger |
|||
|
Fecha: 05/03/07 Hora: 09:58 |
|||
|
Muestra: 1955:3 2000:4 |
|||
|
Rezagos: 6 |
|||
|
Hipótesis nula: |
Obs |
F0 |
Probabilidad |
|
RPCEC1 no causa a la Granger a RGDP1 |
182 |
3.96948 |
0.00097 |
|
RGDP1 no causa a la Granger a RPCEC1 |
1.57954 |
0.15589 |
|
|
RFEDFUNDS no causa a la Granger a RGDP1 |
182 |
4.38935 |
0.00038 |
|
RGDP1 no causa a la Granger a RFEDFUNDS |
3.65417 |
0.00196 |
|
|
DROILPRICE no causa a la Granger a RGDP1 |
182 |
2.54187 |
0.02210 |
|
RGDP1 no causa a la Granger a DROILPRICE |
0.83703 |
0.54289 |
|
|
RGPDI1 no causa a la Granger a RGDP1 |
182 |
1.41485 |
0.21156 |
|
RGDP1 no causa a la Granger a RGPDI1 |
5.26584 |
5.3E-05 |
|
|
RFEDFUNDS no causa a la Granger a RPCEC1 |
182 |
2.71249 |
0.01538 |
|
RPCEC1 no causa a la Granger a RFEDFUNDS |
2.58367 |
0.02026 |
|
|
DROILPRICE no causa a la Granger a RPCEC1 |
182 |
2.59140 |
0.01988 |
|
RPCEC1 no causa a la Granger a DROILPRICE |
1.11272 |
0.35695 |
|
|
RGPDI1 no causa a la Granger a RPCEC1 |
182 |
1.42293 |
0.20848 |
|
RPCEC1 no causa a la Granger a RGPDI1 |
8.80513 |
2.4E-08 |
|
|
DROILPRICE no causa a la Granger a RFEDFUNDS |
182 |
2.90219 |
0.01021 |
|
RFEDFUNDS no causa a la Granger a DROILPRICE |
1.54941 |
0.16508 |
|
|
RGPDI1 no causa a la Granger a RFEDFUNDS |
182 |
2.40961 |
0.02930 |
|
RFEDFUNDS no causa a la Granger a RGPDI1 |
5.82145 |
1.6E-05 |
|
|
RGPDI1 no causa a la Granger a DROILPRICE |
182 |
0.59772 |
0.73189 |
|
DROILPRICE no causa a la Granger a RGPDI1 |
2.88434 |
0.01058 |
|
Fuente: Elaboración propia.
Concluimos que existe causalidad bidireccional entre RFEDFUNDS y las variables: RGPDI1, RGDP1 y entre RPCEC1. La causalidad unidireccional se da entre DROILPRICE y las variables: RGDP1, RPCEC1, RGPDI1 y RFEDFUNDS.
En otras palabras, y basándonos en los resultados anteriores, podemos afirmar que la variable DROILPRICE más exógena que RFEDFUNDS.
- Funciones impulso – respuesta:
La función impulso – respuesta, constituye la representación ![]() del polinomio autorregresivo del modelo. Estas funciones son interesantes entre otras cosas porque nos permiten pensar en “causas” y “efectos”. A manera de ejemplo, digamos que estamos modelando un VAR con las variables PIB y M1, entonces podríamos calcular la respuesta del PIB a un shock monetario en un modelo VAR: PIB – M1 e interpretar dicho resultado como “el efecto” de la política monetaria sobre el PIB.
del polinomio autorregresivo del modelo. Estas funciones son interesantes entre otras cosas porque nos permiten pensar en “causas” y “efectos”. A manera de ejemplo, digamos que estamos modelando un VAR con las variables PIB y M1, entonces podríamos calcular la respuesta del PIB a un shock monetario en un modelo VAR: PIB – M1 e interpretar dicho resultado como “el efecto” de la política monetaria sobre el PIB.
Una función de impulso – respuesta, explica la respuesta del sistema a shocks en los componentes del vector de perturbaciones (en una desviación típica por lo general). Un shock en una variable en el período i, afectará de manera directa a la propia variable y se transmitirá al resto de variables explicadas por medio de la estructura dinámica que representa el modelo VAR.
Sin embargo, las funciones de impulso – respuesta de un VAR son ligeramente ambiguas, esto se debe a que existen correlaciones entre las perturbaciones de las distintas ecuaciones (correlación cruzada) y no es posible diferenciar con claridad los efectos individuales de cada perturbación a no ser que se efectué una transformación previa.
Cuando simulamos un VAR por medio de una función impulso - respuesta, lo hacemos mediante una ortogonalización de las perturbaciones aleatorias, es decir, se debe transformar el modelo original para diagonalizar la matriz de varianzas y covarianzas de las perturbaciones. Sims (1980), propuso usar la factorización de Choleski. En esta factorización, asumimos que toda la perturbación aleatoria de la primera ecuación corresponde a la primera variable, es decir, que no existe efecto adicional procedente de las siguientes variables; la perturbación de la segunda ecuación proviene de la primera y de la suya propia, y así sucesivamente a lo largo de una cadena causal. Aunque el uso del método de factorización de Choleski ha sido usado ampliamente, no deja de ser un tanto arbitrario a la hora de atribuir los efectos comunes.
Por otra parte, si se cambia el orden de las variables, los resultados de las funciones impulso – respuesta pueden variar drásticamente por lo que ordenaciones distintas nos conducen a alternativas diferentes en el proceso de simulación9, 10.
- Descomposición de la varianza del error de predicción:
Constituye otra herramienta de simulación de los modelos VAR, consiste en determinar, para cada horizonte de predicción k, qué porcentaje de las variaciones de cada variable Yi , t + k es explicado por cada perturbación ui , t + k . En otras palabras, proporciona información sobre la importancia relativa de cada perturbación aleatoria de las variables en el modelo VAR.
Se debe advertir además que las simulaciones con modelos VAR (usando las funciones de impulso – respuesta y/o el análisis de la descomposición de la varianza del error de predicción) son atemporales, en el sentido de que únicamente recogen la influencia de acuerdo con el transcurso del tiempo, sin embargo no se encuentran asociadas a un período específico.
A continuación, se presenta el resultado del proceso de simulación:
|
Descomposición de la varianza de RGDP1 |
||||||
|
Período |
Desv.típica |
RGDP1 |
RPCEC1 |
RGPDI1 |
RFEDFUNDS |
DROILPRICE |
|
1 |
0.0088 |
100 |
||||
|
4 |
0.01738 |
87.99 |
4.56 |
1.3295 |
2.97 |
3.13 |
|
8 |
0.02167 |
61.27 |
8.18 |
3.235 |
14.77 |
12.54 |
|
12 |
0.0227 |
56.8 |
10.56 |
4.9 |
15.58 |
12.16 |
|
16 |
0.0234 |
53.41 |
11.55 |
6.57 |
15.08 |
13.38 |
|
20 |
0.0236 |
53.29 |
11.56 |
6.53 |
15.14 |
13.47 |
|
24 |
0.0237 |
53.27 |
11.79 |
6.48 |
15.06 |
13.4 |
|
Descomposición de la varianza de RPCEC1 |
||||||
|
Período |
Desv.típica |
RGDP1 |
RPCEC1 |
RGPDI1 |
RFEDFUNDS |
DROILPRICE |
|
1 |
0.0072 |
41.23 |
58.77 |
|||
|
4 |
0.0139 |
48.61 |
40.99 |
2.18 |
5.53 |
2.68 |
|
8 |
0.0165 |
37.27 |
30.12 |
4.73 |
13.55 |
14.32 |
|
12 |
0.0170 |
36.09 |
30.03 |
5.47 |
13.53 |
14.87 |
|
16 |
0.0174 |
34.74 |
29.4 |
6.65 |
14.02 |
15.18 |
|
20 |
0.0176 |
34.68 |
29.21 |
6.54 |
14.44 |
15.13 |
|
24 |
0.0177 |
34.68 |
29.48 |
6.46 |
14.42 |
14.95 |
|
Descomposición de la varianza de RGPDI1 |
||||||
|
Período |
Desv.típica |
RGDP1 |
RPCEC1 |
RGPDI1 |
RFEDFUNDS |
DROILPRICE |
|
1 |
0.043 |
56.7 |
19.11 |
24.19 |
||
|
4 |
0.071 |
63.05 |
9.11 |
25.26 |
1.89 |
0.68 |
|
8 |
0.092 |
46.81 |
16.67 |
16.97 |
11.08 |
8.46 |
|
12 |
0.1003 |
43.28 |
20.11 |
17.64 |
11.36 |
7.6 |
|
16 |
0.1044 |
40.12 |
21.16 |
19.38 |
11.75 |
7.58 |
|
20 |
0.105 |
39.74 |
21.08 |
19.23 |
11.7 |
8.25 |
|
24 |
0.1052 |
39.72 |
21.15 |
19.16 |
11.67 |
8.3 |
Fuente: elabolación propia
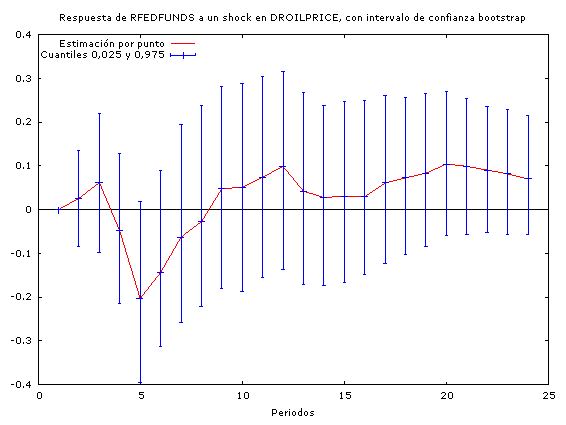
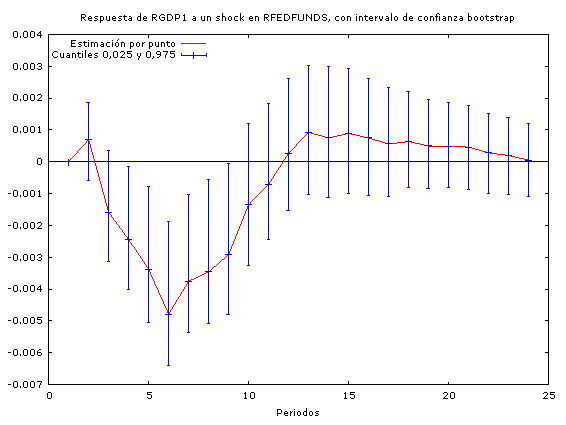
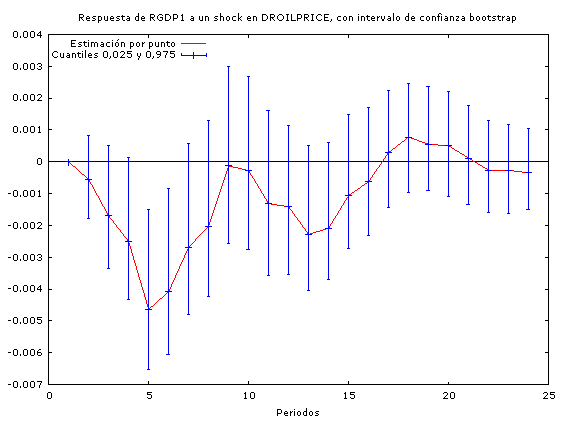
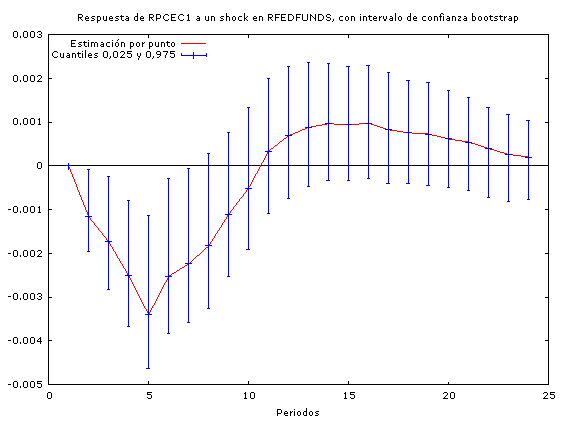
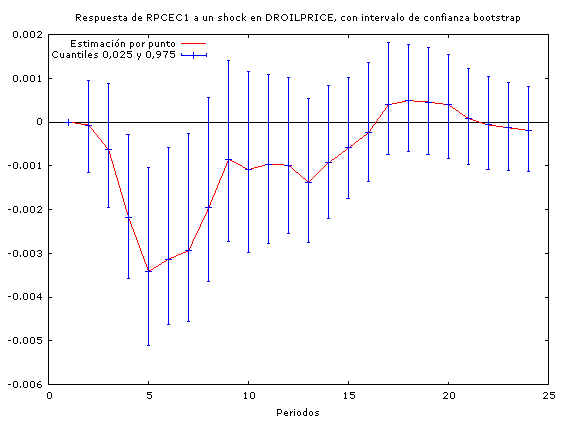
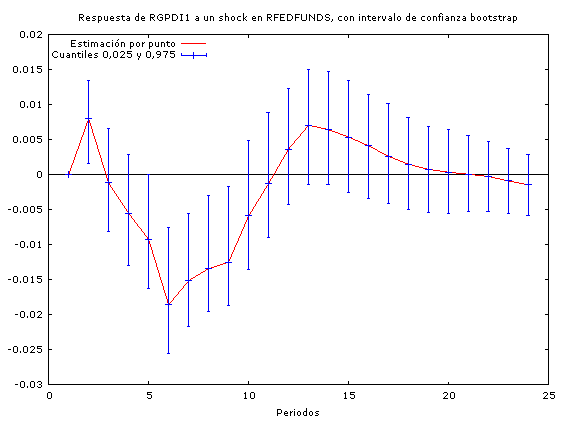
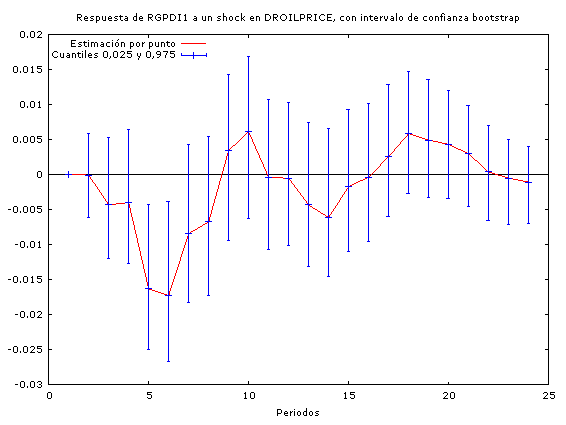
A través de estos análisis podemos constatar que los incrementos en los precios del petróleo conducen a un incremento en las tasas de interés (por tanto concluimos que la política monetaria no es neutral ante los shocks petroleros) y a una baja en el PIB real (y por tanto en la actividad económica agregada).
En cuanto a la duración de los efectos de las perturbaciones, se observa que los impactos de los incrementos en los precios del petróleo son mayores que los impactos que tiene la política monetaria sobre la economía a la hora de encarar un shock petrolero.
- Pronósticos dinámicos.
Un modelo de series de tiempo (ya sea univariante o bien multivariante) se utiliza en la mayoría de los casos para fines de pronósticos. Por otro lado, cabe destacar que el proceso de construcción misma de un modelo está íntimamente vinculado con el pronóstico debido a que para calcular los residuales se deben de obtener primero los valores estimados (ajustados) por el modelo, que no son otra cosa más que los valores pronosticados de la variable en el período t, con base en las observaciones hasta el período t – 1 (pronósticos de un período hacia delante).
El pronóstico involucra simular el modelo adelante en el tiempo y fuera del período de estimación. Es posible distinguir dos tipos de pronósticos: Si el período de estimación no se extiende hasta el año actual (es decir T2 < T3), podríamos comenzar el pronóstico al final del período de estimación y extenderlo hasta el presente, posiblemente comparando los resultados con los datos disponibles. Esto es denominado como “pronóstico ex post” y se realiza con frecuencia como una forma de probar la precisión de pronóstico de un modelo11. Un pronóstico que se efectúa iniciando la simulación en el año actual y extendiéndola hacia el futuro se llama “pronóstico ex ante”.
Por otro lado, en muchas ocasiones, es de particular interés simular el modelo retrocediendo en el tiempo, iniciando al principio del período de estimación. Esto se puede hacer cuando deseamos probar la estabilidad dinámica del modelo o para desarrollar análisis de las diferentes hipótesis sobre eventos que se realizaron antes del período de estimación. Este tipo de pronóstico se denomina retropronóstico.
La figura mostrada a continuación, resume los tipos de pronósticos que existen.
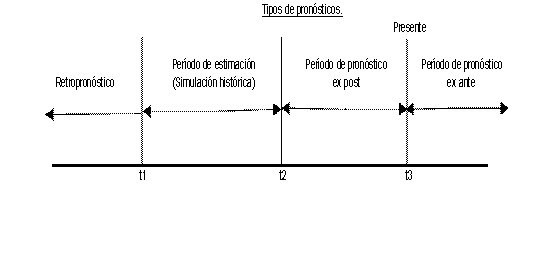
Fuente: Pindyck R.S y Rubinfeld D.L (1998). Econometría: modelos y pronósticos.
Existen también diferentes criterios usados para evaluar pronósticos. El primero es el ajuste de las ecuaciones individuales en un contexto de simulación histórica, es de esperarse que los resultados de dicha simulación concuerden con el comportamiento del mundo real de una forma muy cercana.
Otro criterio que se utiliza es el uso de estadísticos como el error de pronóstico rms, error porcentual rms, error de simulación medio y error porcentual medio. Estos estadísticos que son en cierta forma medidas de bondad de ajuste, se calculan mediante las siguientes fórmulas13:
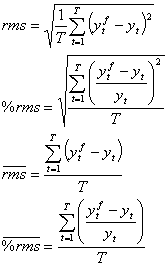
Donde: ![]() = Valor ajustado de
= Valor ajustado de ![]()
![]() = Valor real de
= Valor real de ![]()
T = Número de períodos.
El siguiente criterio utilizado consiste en apreciar si la serie pronosticada es capaz de captar los virajes de la serie real. Por otra parte, una desventaja de los modelos de ecuaciones simultáneas (los modelos VAR son considerados también modelos de ecuaciones simultáneas) es que a diferencia de los modelos uniecuacionales no existe una forma simple de calcular los intervalos de confianza debido a que los errores de pronóstico pueden estar compuestos de una manera compleja por la estructura de retroalimentación del modelo. Sin embargo, en estudios recientes, ha sido posible computar intervalos de confianza para pronóstico utilizando simulación estocástica (Métodos de Montecarlo por ejemplo) 12.
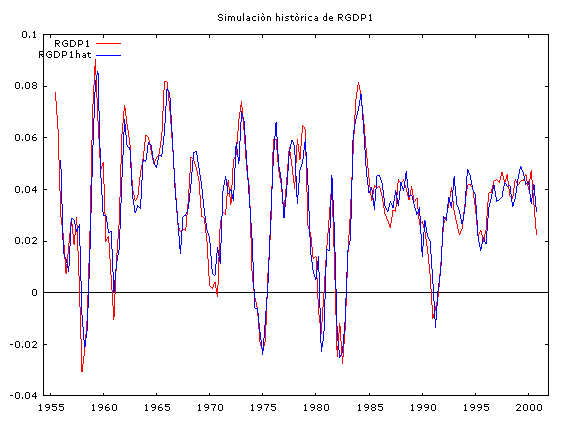
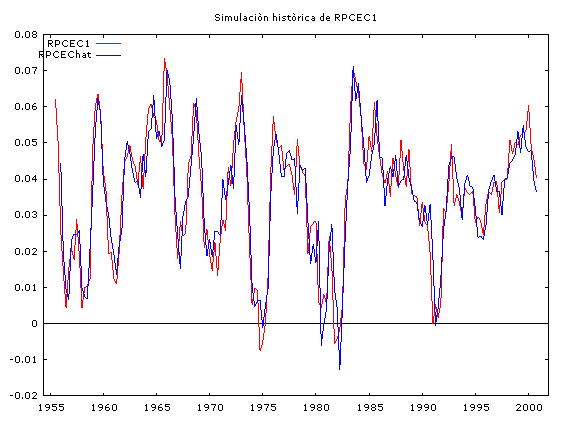
A continuación se muestran las simulaciones históricas, el cálculo de los estadísticos de bondad de ajuste y los pronósticos ex post para las variables: RGDP1, RPCEC1 y RGPDI1.
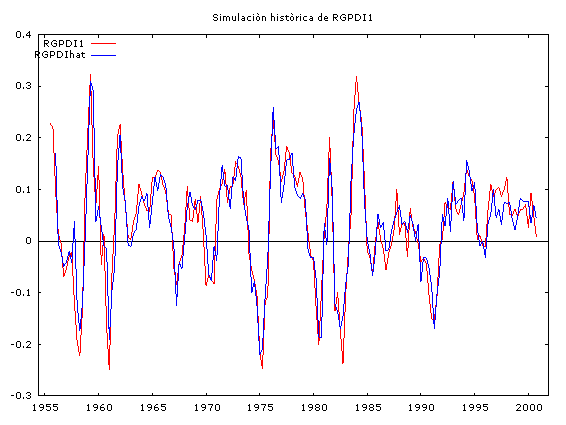
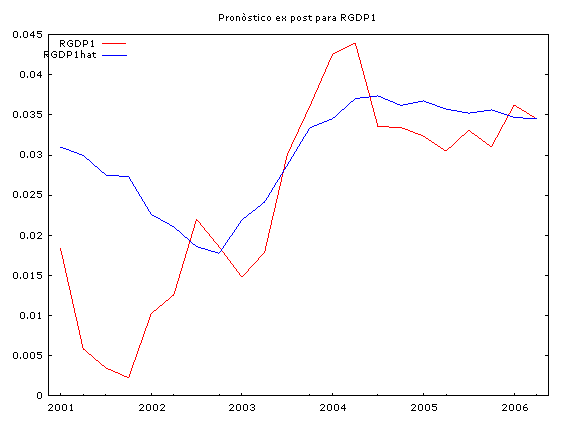
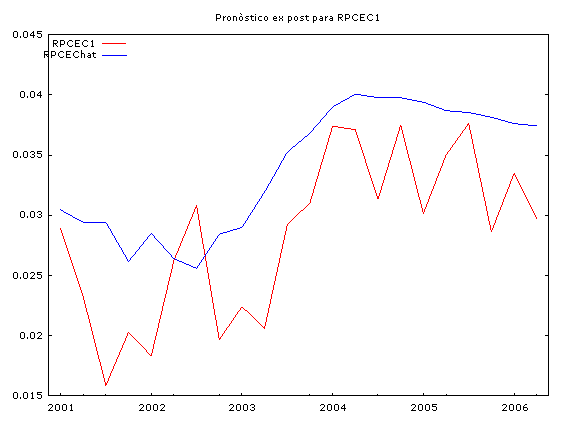
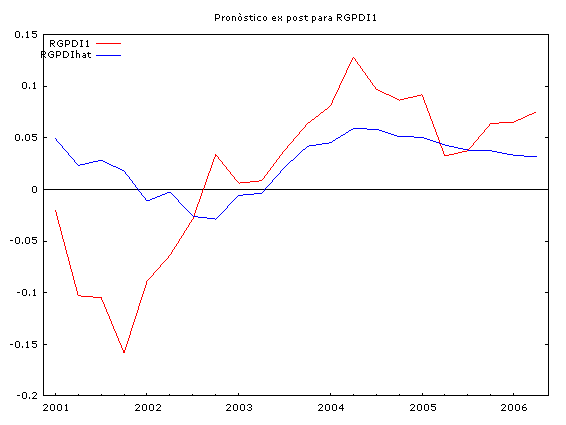
|
Resumen de estadísticas para pronóstico ex post T = 22 |
|||
|
RGDP1 |
RPCEC1 |
RGPDI1 |
|
|
Media (serie real) |
0.0247028 |
0.02838598 |
0.01551654 |
|
Error rms |
0.01063515 |
0.00694855 |
0.06691845 |
|
Error porcentual rms |
2.94235021 |
0.32119375 |
1.16271735 |
|
Error medio |
-0.00536945 |
-0.0055083 |
-0.00953571 |
|
Error porcentual medio |
-1.15887003 |
-0.23356501 |
0.8374362 |
Fuente: Elaboración propia.
Observamos que en el proceso de simulación histórica, las series simuladas reproducen bastante bien el comportamiento de las series reales. Sin embargo, las estadísticas de bondad de ajuste para el pronóstico ex post de 22 períodos hacia adelante (2001:01 hasta 2006:02), nos indican la presencia de un sesgo sistemático (sin embargo, los valores pronosticados no divergen mucho de los valores reales) a pesar de eso, las series pronosticadas captan muy bien los puntos de viraje de las series reales.
Este comportamiento es típico de los vectores autorregresivos, por tal razón ellos son una herramienta útil para pronósticos a corto plazo.
zonaeconomica.com "Construcción, evaluación y uso del modelo" [en linea]
Dirección URL: https://www.zonaeconomica.com/node/919 (Consultado el 24 de Mar de 2026)